Homework 2 (hw2) has been released (Due: Jan 20, 11:59pm)
There is some autograding in this homework.
You can find the tentative due dates for all deliverables here.
Please monitor Piazza (especially pinned posts and instructor posts) for announcements.
I’ll assume that you’ve watched the pre-lecture videos.
Suggested workflow for working with Jupyter Notebooks
Create a folder on your computer that will have all the CPSC 330 repos:
~/School/Year3/CPSC330/ <– Consider this your CPSC parent folder
Create subfolders for: hw, class, practice
In the hw folder, you will then clone hw1, hw2, hw3, etc…
In the class folder, you will clone the CPSC330-2024W2 repo which contains all the class jupyter notebooks
Do not make any changes to files in this directory/repo, you will have trouble when you pull stuff during each class.
If you did make changes, you can reset to the last commit and DESTROY any changes you made (be careful with this command) using: git reset --hard
In the practice folder, you can copy any notebooks (.ipynb) and files (like data/*.csv) you want to try running locally and experiment
Learning outcomes
From this lecture, you will be able to
Identify whether a given problem could be solved using supervised machine learning or not;
Differentiate between supervised and unsupervised machine learning;
Explain machine learning terminology such as features, targets, predictions, training, and error;
Differentiate between classification and regression problems;
Learning outcomes (contd)
Use DummyClassifier and DummyRegressor as baselines for machine learning problems;
Explain the fit and predict paradigm and use score method of ML models;
Broadly describe how decision tree prediction works;
Use DecisionTreeClassifier and DecisionTreeRegressor to build decision trees using scikit-learn;
Visualize decision trees;
Explain the difference between parameters and hyperparameters;
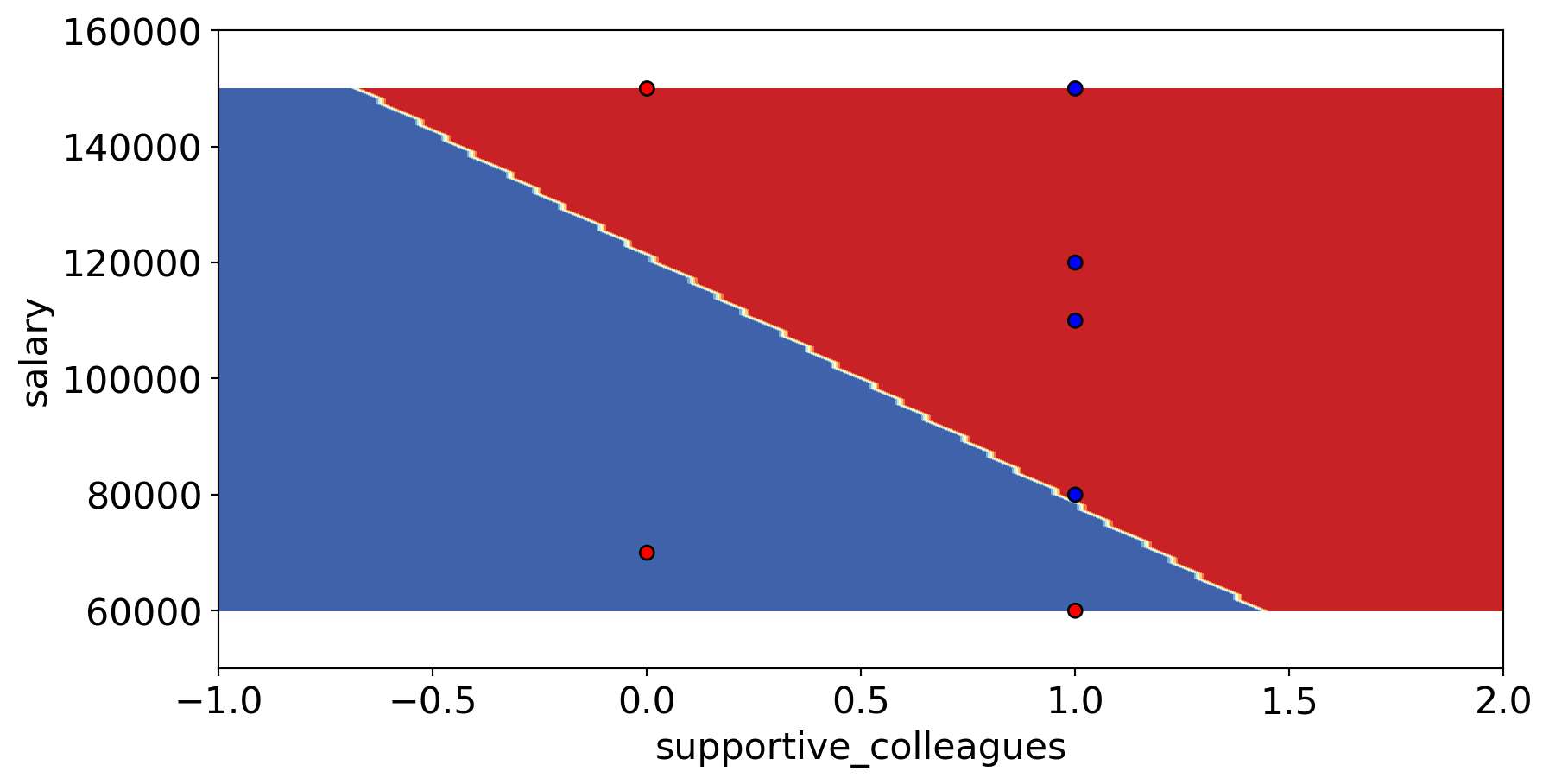
Explain the concept of decision boundaries;
Explain the relation between model complexity and decision boundaries.
Big picture
In this lecture, we’ll talk about our first machine learning model: Decision trees. We will also familiarize ourselves with some common terminology in supervised machine learning.
Recap: What is ML?
ML uses data to build models that find patterns, make predictions, or generate content.
It helps computers learn from data to make decisions.
No one model works for every situation.
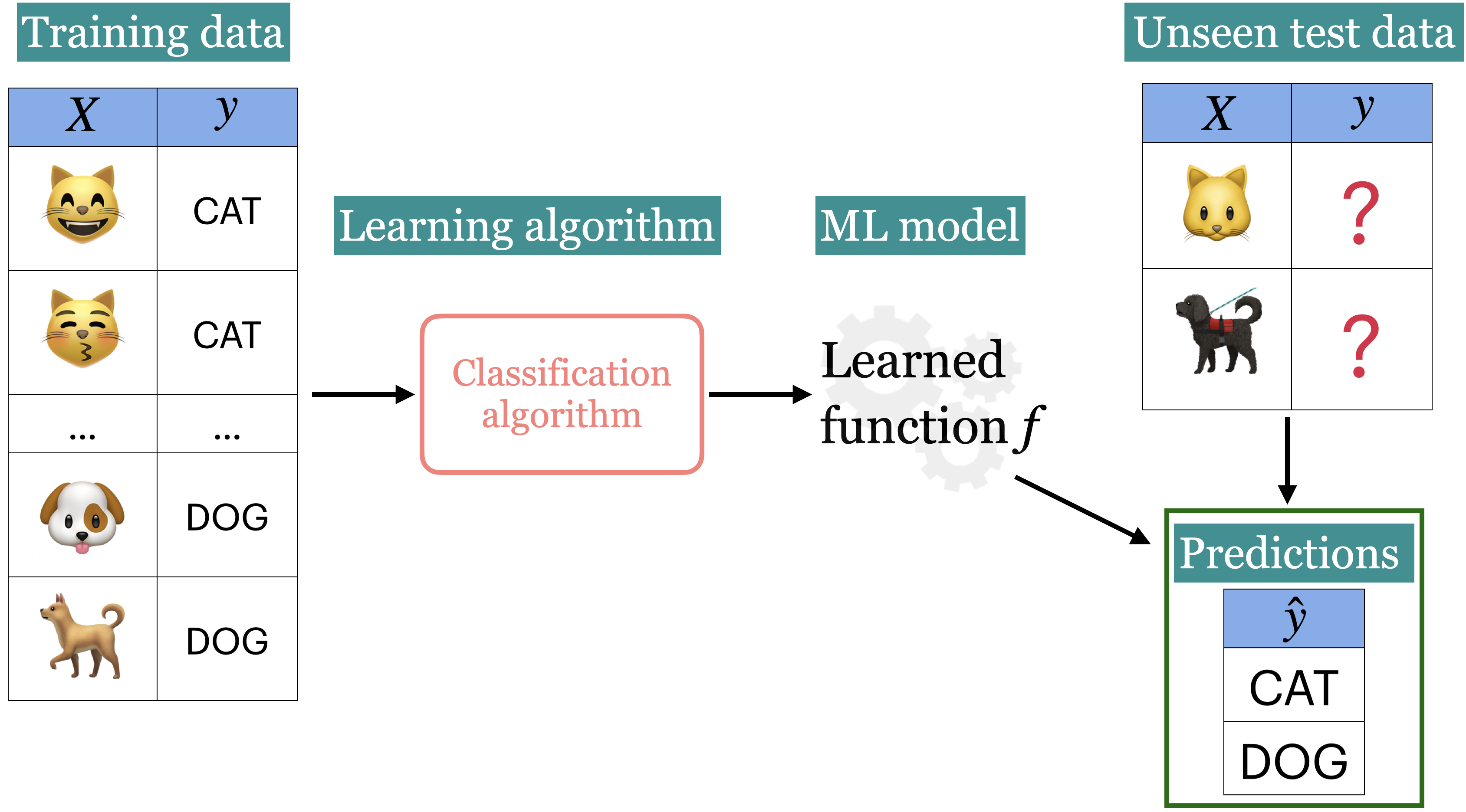
Recap: Supervised learning
We wish to find a model function f that relates X to y.
We use the model function to predict targets of new examples.
In the first part of this course, we’ll focus on supervised machine learning.
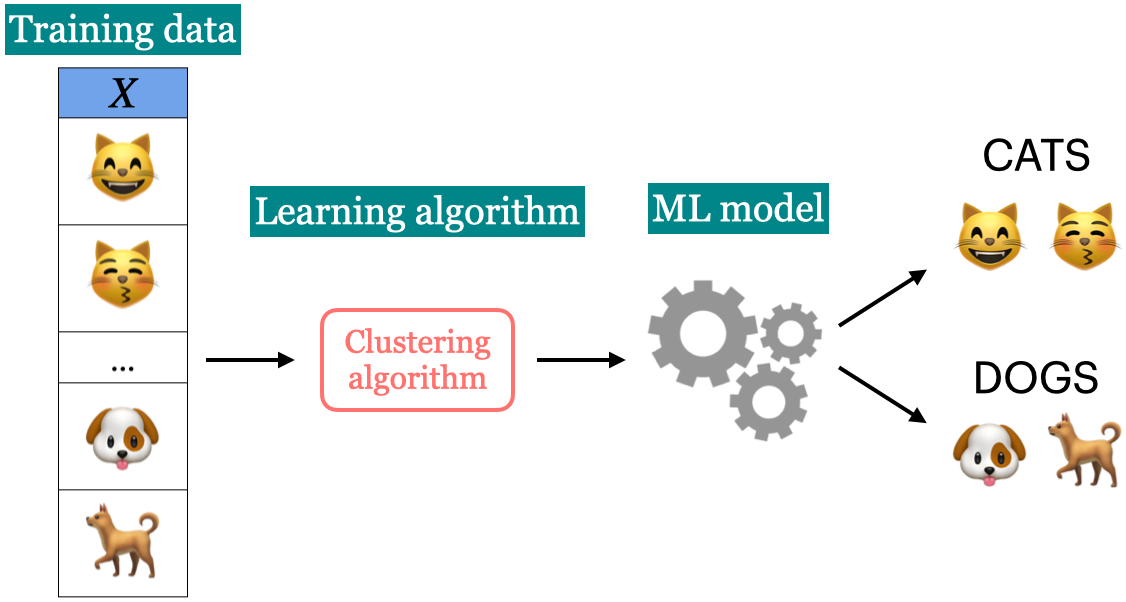
Unsupervised learning
In unsupervised learning training data consists of observations (X) without any corresponding targets.
Unsupervised learning could be used to group similar things together in X or to provide concise summary of the data.
Imagine you’re in the fortunate situation where, after graduating, you have a few job offers and need to decide which one to choose. You want to pick the job that will likely make you the happiest. To help with your decision, you collect data from like-minded people. Here are the first few rows of this toy dataset.
Select all of the following statements which are examples of regression problems
Predicting the price of a house based on features such as number of bedrooms and the year built.
Predicting if a house will sell or not based on features like the price of the house, number of rooms, etc.
Predicting percentage grade in CPSC 330 based on past grades.
Predicting whether you should bicycle tomorrow or not based on the weather forecast.
Predicting appropriate thermostat temperature based on the wind speed and the number of people in a room.
Classification vs. Regression
Is this a classification problem or a regression problem?
supportive_colleagues
salary
free_coffee
boss_vegan
happy?
0
0
70000
0
1
Unhappy
1
1
60000
0
0
Unhappy
2
1
80000
1
0
Happy
3
1
110000
0
1
Happy
4
1
120000
1
0
Happy
5
1
150000
1
1
Happy
6
0
150000
1
0
Unhappy
Prediction vs. Inference
Inference is using the model to understand the relationship between the features and the target
Why certain factors influence happiness?
Prediction is using the model to predict the target value for new examples based on learned patterns.
Of course these goals are related, and in many situations we need both.
Training
In supervised ML, the goal is to learn a function that maps input features (X) to a target (y).
The relationship between X and y is often complex, making it difficult to define mathematically.
We use algorithms to approximate this complex relationship between X and y.
Training is the process of applying an algorithm to learn the best function (or model) that maps X to y.
In this course, I’ll help you develop an intuition for how these models work and demonstrate how to use them in a machine learning pipeline.
Baselines
Separating X and y
In order to train a model we need to separate X and y from the dataframe.
# Extract the feature set by removing the target column "happy?"X = toy_happiness_df.drop(columns=["happy?"])# Extract the target variable "happy?"y = toy_happiness_df["happy?"]
Baseline
Let’s try a simplest algorithm of predicting the most popular target!
from sklearn.dummy import DummyClassifier# Initialize the DummyClassifier to always predict the most frequent classmodel = DummyClassifier(strategy="most_frequent") # Train the model on the feature set X and target variable ymodel.fit(X, y)# Add the predicted values as a new column in the dataframetoy_happiness_df['dummy_predictions'] = model.predict(X) toy_happiness_df
supportive_colleagues
salary
free_coffee
boss_vegan
happy?
dummy_predictions
0
0
70000
0
1
Unhappy
Happy
1
1
60000
0
0
Unhappy
Happy
2
1
80000
1
0
Happy
Happy
3
1
110000
0
1
Happy
Happy
4
1
120000
1
0
Happy
Happy
5
1
150000
1
1
Happy
Happy
6
0
150000
1
0
Unhappy
Happy
score your model
How do you know how well your model is doing?
For classification problems, by default, score gives the accuracy of the model, i.e., proportion of correctly predicted targets.
You can also do the same thing for regression problems using DummyRegressor, which predicts mean, median, or constant value of the training set for all examples.
Decision trees
Pre-Intuition
Let’s play 20 questions! You can ask me up to 20 Yes/No questions to figure out the answer.
Intuition
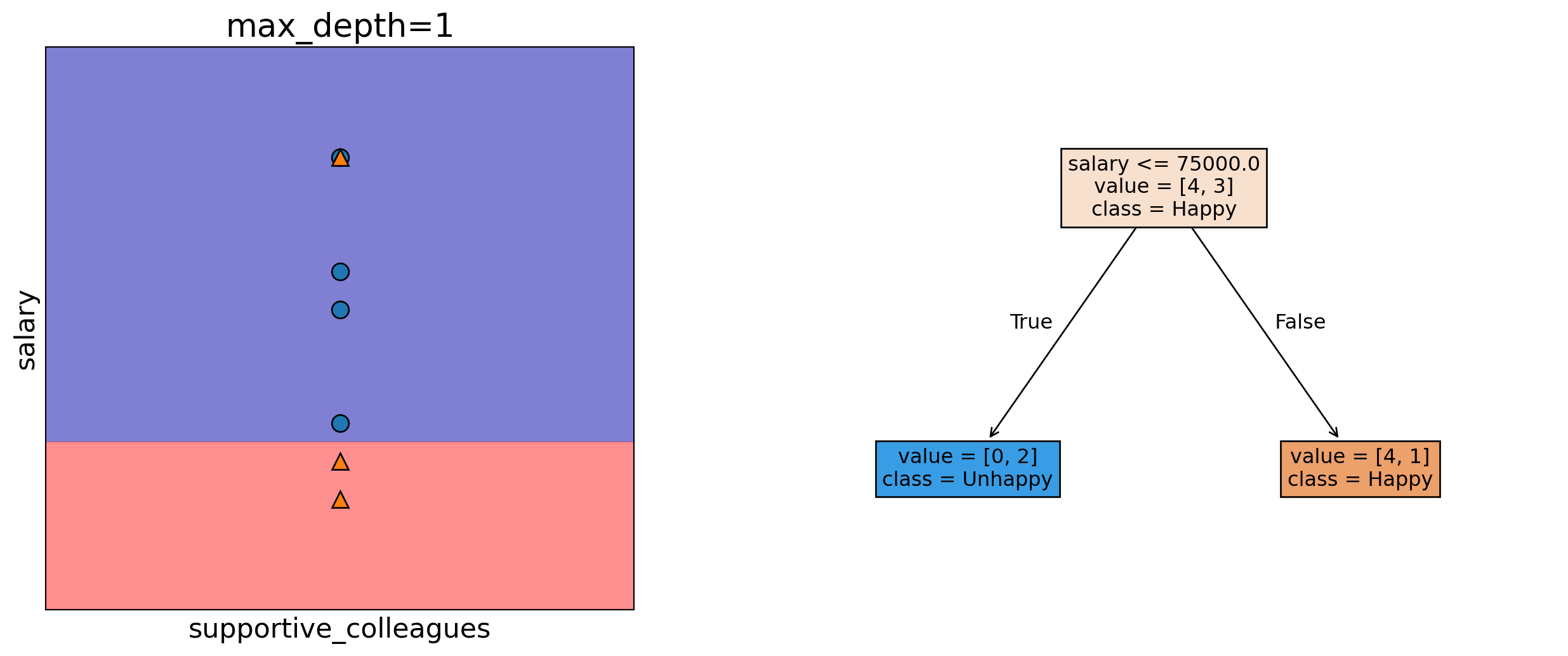
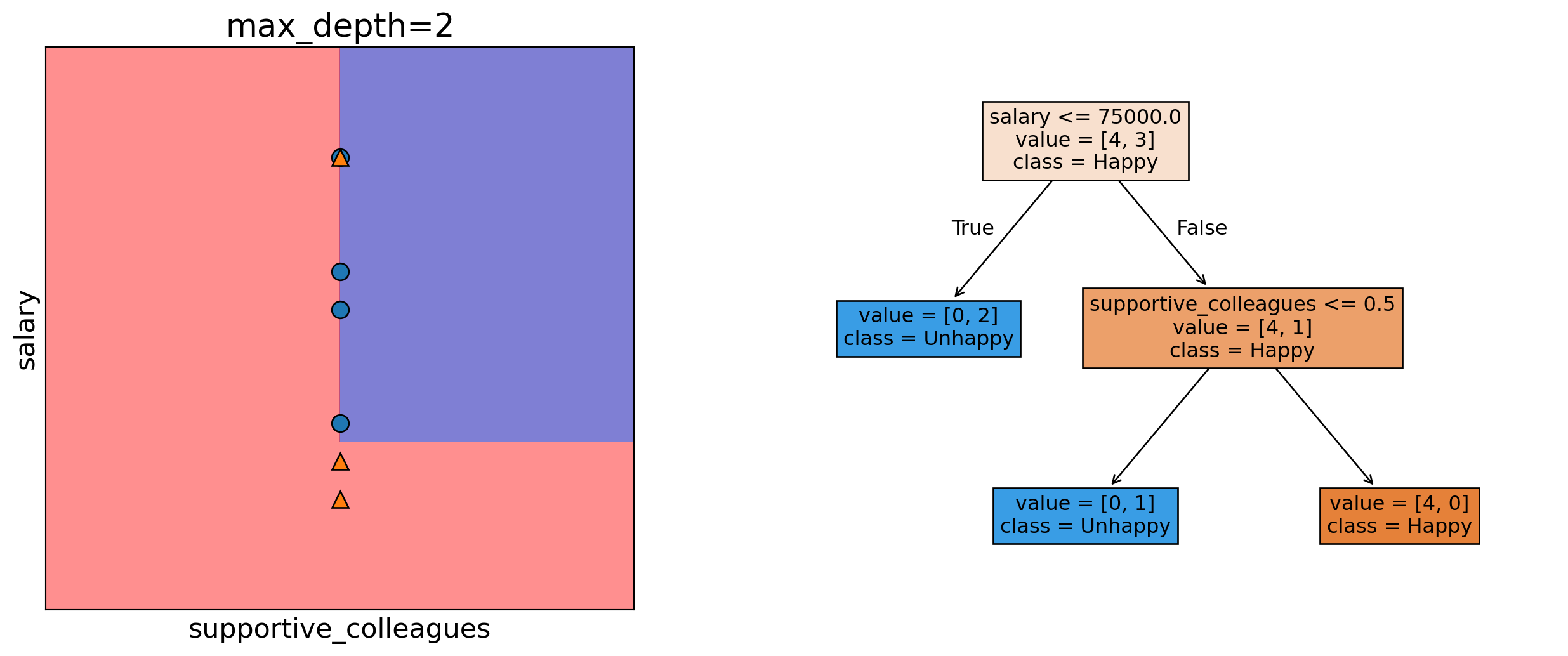
Decision trees find the “best” way to split data to make predictions.
Each split is based on a question, like ‘Are the colleagues supportive?’
The goal is to group data by similar outcomes at each step.
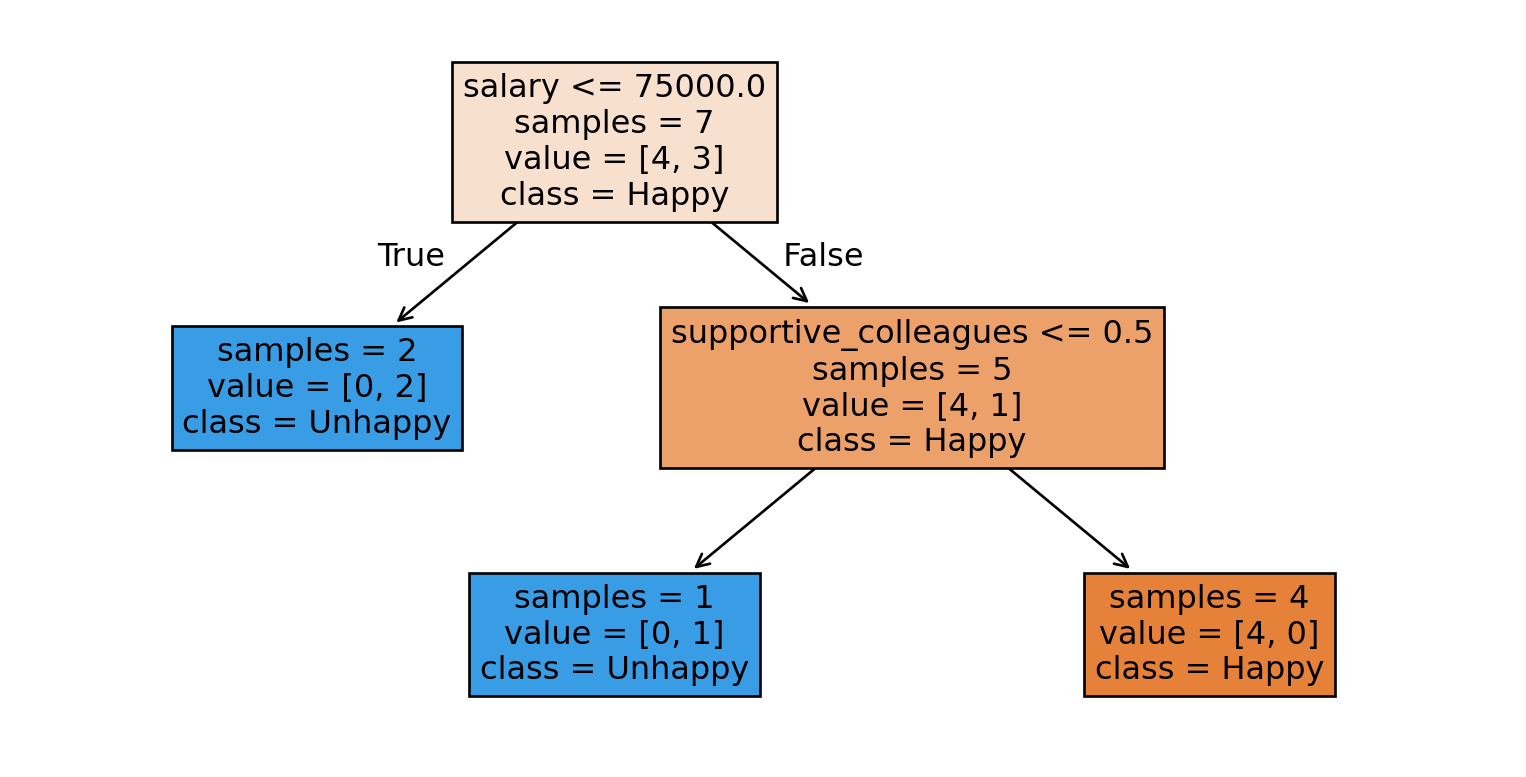
Now, let’s see a decision tree using sklearn.
Decision tree with sklearn
Let’s train a simple decision tree on our toy dataset.
from sklearn.tree import DecisionTreeClassifier # import the classifierfrom sklearn.tree import plot_tree# Create a decision tree objectmodel = DecisionTreeClassifier(max_depth=2, random_state=1)# Train the model on the feature set X and target variable ymodel.fit(X, y)plot_tree( model, filled=True, feature_names=X.columns, class_names=["Happy", "Unhappy"], impurity=False, fontsize=12);
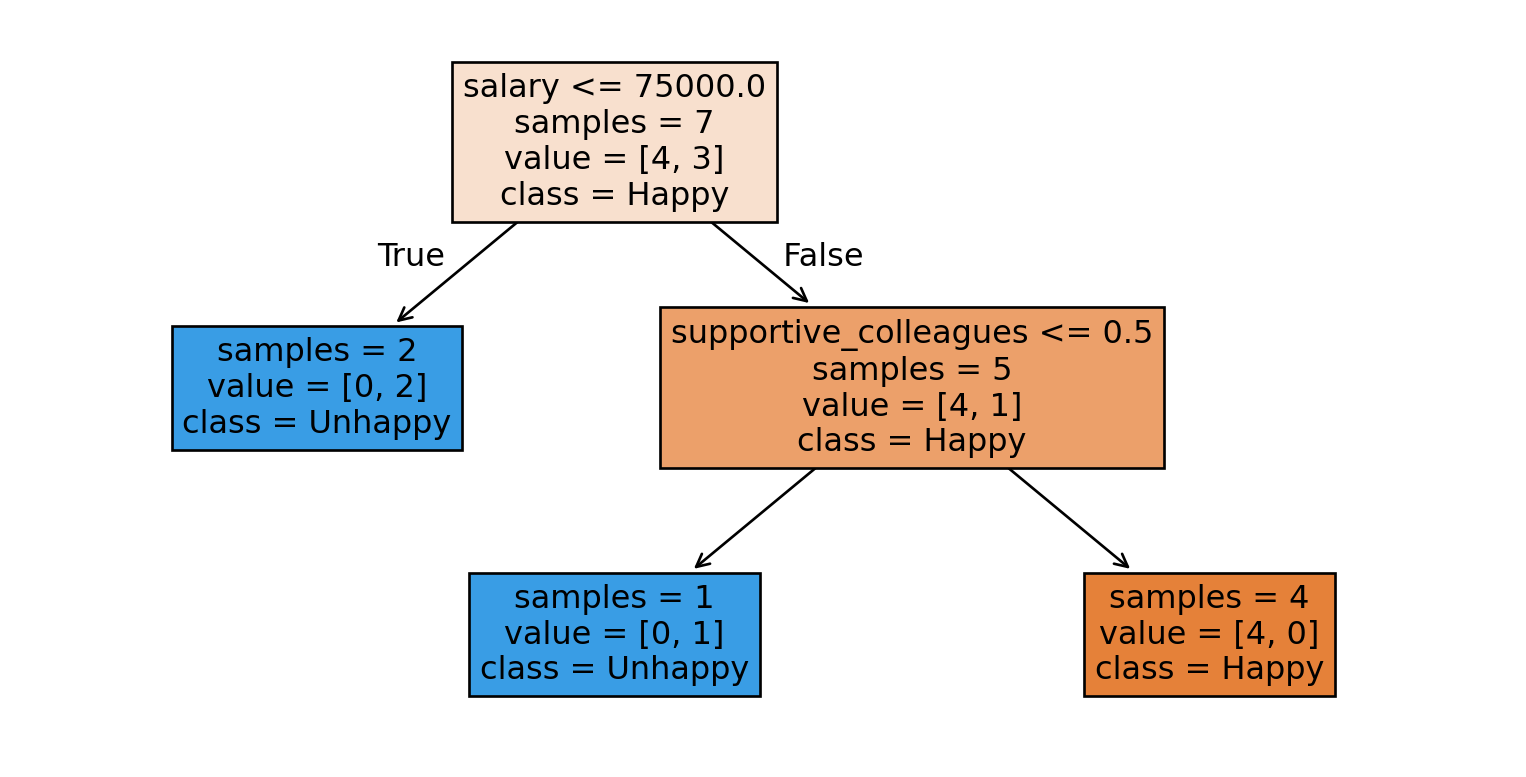
Prediction
Given a new example, how does a decision tree predict the class of this example?
What would be the prediction for the example below using the tree above?